


rewrite this content and keep HTML tags as is. This is content from rss feed and I don’t need their *Daily Debrief Newsletter*, their tags from bottom like this *Share this articleCategoriesTags*, Editorial Process section, phrases like *Featured image from Peakpx, chart from Tradingview.com*, SPECIAL OFFERS and similar sections – just remove such sections and save only article itself:
Liquid AI just shipped LFM2.5-8B-A1B. It is an on-device Mixture-of-Experts (MoE) model built for tool calling. The model holds 8.3B total parameters but activates only 1.5B per token. That sparsity is what lets it run on consumer hardware.
The release follows LFM2-8B-A1B, which Liquid AI team published earlier. LFM2.5 is a new family of hybrid models for on-device deployment. This version adds a 128K context window, reasoning, and scaled-up training.
What is LFM2.5-8B-A1B
The model uses a sparse MoE design. It activates 1.5B of 8.3B total parameters per forward pass. That keeps each generated token cheap to compute.
The architecture has 24 layers. Eighteen are double-gated LIV convolution blocks; six are GQA layers. It combines MoE, GQA, and gated short convolution blocks. The context length is 131,072 tokens. The model covers nine languages, including Arabic, Chinese, and Japanese.

Liquid AI team recommends a temperature of 0.2, top_k of 80, and repetition_penalty of 1.05.
Unlike its predecessor, LFM2.5-8B-A1B is a reasoning-only model. It produces an explicit chain of thought before its final answer. Liquid AI team chose this because MoE models run in compute-bound settings. A smaller active parameter count makes each reasoning token inexpensive.
What Changed Since LFM2-8B-A1B
Liquid expanded the context window from 32,768 to 128,000 tokens. Pretraining scaled from 12T to 38T tokens. The vocabulary doubled from 65,536 to 128,000 tokens.
The larger vocabulary tokenizes non-Latin scripts more efficiently. Liquid AI team reports the strongest compression gains in Hindi, Thai, Vietnamese, Indonesian, and Arabic. The rest of the architecture stays the same as LFM2-8B-A1B.
How Liquid AI Trained It
Liquid AI team extended the tokenizer in place rather than retraining from scratch. It continued BPE merge training from the original merges on a multilingual corpus. New embedding rows initialize as the mean of their sub-token decompositions. A brief two-stage adaptation then recovers quality.
Context extension came in two phases. A 2T token midtraining phase reached 32K, focused on reasoning, math, and tool use. Raising the RoPE base θ, plus a 400B token stage, reached 128K.
Two reinforcement learning stages target known failure modes. A preference optimization stage reduces ‘doom loops’ in long reasoning traces. It redistributes probability mass toward plausible alternatives. A separate RL shaping reward discourages loop-inducing restart words like ‘Wait…’. Another RL stage uses an avg@k-based reward to cut hallucinations. The goal is abstention on queries beyond reliable knowledge.
The Benchmark Case
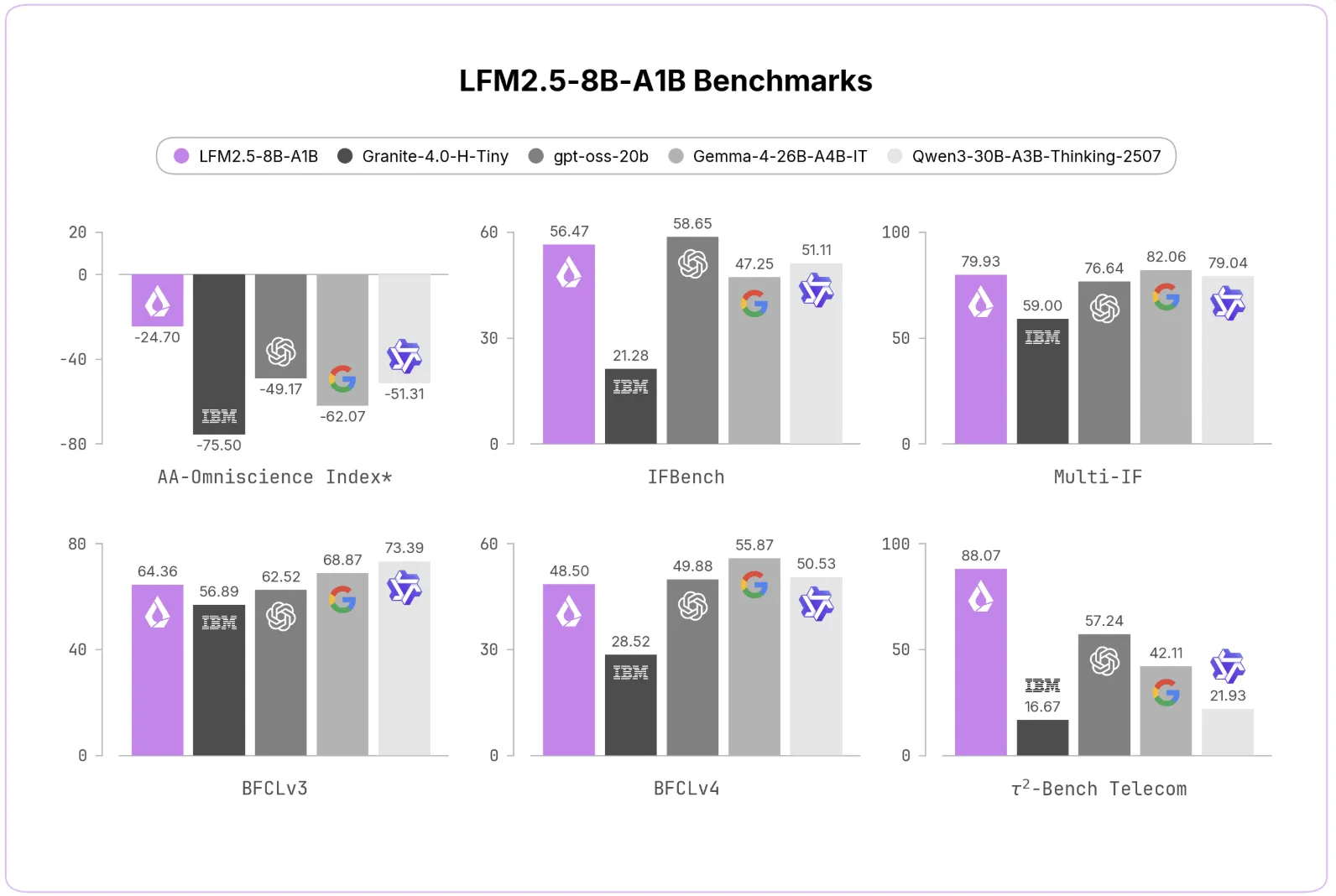
LFM2.5-8B-A1B improves over its predecessor across the board. The AA-Omniscience Non-Hallucination Rate jumped from 7.46 to 63.47. IFEval rose from 79.44 to 91.84. MATH500 climbed from 74.80 to 88.76. Tau² Telecom rose from 13.60 to 88.07.
Liquid AI team compared the model against dense and MoE alternatives. On instruction following, it matches Gemma-4-26B-A4B-IT on IFEval. It does so at a fraction of the active parameter count. On Tau² Telecom, it scores 88.07, ahead of much larger models.
The avg@k reward drives a much lower hallucination rate. Accuracy stays reasonable for the model’s size. On agentic benchmarks, it remains competitive with bigger models.
The model ships with day-one support across the inference ecosystem. Frameworks include llama.cpp, MLX, vLLM, and SGLang. ONNX and Liquid’s LEAP edge platform are also supported.
On CPU, it decodes 253 tokens/s on an M5 Max. It reaches 146 tokens/s on a Ryzen AI Max+ 395. It stays under 6 GB of memory throughout. On a phone, it holds about 30 tokens/s.
On a single NVIDIA H100 SXM5, output throughput hits 18.5K tokens per second. That is over 1.6B tokens per day at high concurrency.
For tool use, LFM2.5 writes Pythonic function calls by default. They appear between the <|tool_call_start|> and <|tool_call_end|> special tokens. You can override this to JSON in the system prompt.
Strengths and What to Watch
Strengths:
- Activates only 1.5B parameters, keeping inference cheap on edge hardware
- Competitive instruction-following and agentic scores for its size class
- 128K context window and nine-language coverage
- Open-weight under the LFM1.0 license, with base and post-trained checkpoints
What to Watch:
- Limited knowledge capacity from the small active parameter count
- Not a fit for heavy programming or knowledge-intensive QA without retrieval
- Reasoning-only output adds chain-of-thought tokens to every turn
- Text-only; this variant has no vision or audio input
Marktechpost’s Visual Explainer
On-Device Model Guide
LFM2.5-8B-A1B
Liquid AI’s on-device Mixture-of-Experts model, built for tool calling and complex instruction following on consumer hardware.
8.3B total params
1.5B active
128K context
reasoning‑only
open‑weight
What It Is
A sparse MoE that activates 1.5B of 8.3B parameters per token
- 24 layers — 18 double-gated LIV convolution blocks plus 6 GQA layers.
- Combines MoE, GQA, and gated short convolution blocks.
- Context length of 131,072 tokens; covers 9 languages.
- Reasoning-only: produces an explicit chain of thought before answering.
- Recommended params: temperature 0.2, top_k 80, repetition_penalty 1.05.
What Changed Since LFM2-8B-A1B
Bigger context, more training, a wider vocabulary
Context window
32,768 → 128,000
Processes longer documents and reasons for longer.
Pretraining tokens
12T → 38T
Scaled-up pretraining plus large-scale RL.
Vocabulary size
65,536 → 128,000
Tokenizes non-Latin scripts more efficiently.
Best compression gains
5 languages
Hindi, Thai, Vietnamese, Indonesian, Arabic.
How It Was Trained
Tokenizer extension, staged context growth, targeted RL
- Tokenizer: extended in place, with continued BPE merge training on a multilingual corpus.
- Context: a 2T-token midtraining phase to 32K, then RoPE base θ plus 400B tokens to 128K.
- Doom loops: preference optimization redistributes probability mass toward plausible alternatives.
- A separate RL shaping reward discourages loop-inducing restart words like “Wait…”.
- Hallucinations: an avg@k-based RL reward encourages abstention beyond reliable knowledge.
Benchmarks vs LFM2-8B-A1B
Largest gains in non-hallucination and tool use
BenchmarkLFM2LFM2.5Δ
AA-Omniscience Non-Hallucination Rate7.4663.47+56.01
IFEval79.4491.84+12.40
MATH50074.8088.76+13.96
Tau² Telecom13.6088.07+74.47
On IFEval it matches Gemma-4-26B-A4B-IT at a fraction of the active parameter count.
Inference Performance
Fast on CPU and GPU, with day-one framework support
CPU decode
253 tok/s
M5 Max, under 6 GB memory. 146 tok/s on a Ryzen AI Max+ 395.
On a phone
~30 tok/s
Runs locally and privately on device.
GPU throughput
18.5K tok/s
High concurrency, >1.6B tokens/day on a single H100.
Day-one support
llama.cpp, MLX, vLLM, SGLang.
Also ONNX and Liquid’s LEAP.
Tool Use & Agents
Pythonic function calls, ready for on-device agents
- By default, writes Pythonic function calls between <|tool_call_start|> and <|tool_call_end|> tokens.
- You can override this to JSON function calls in the system prompt.
- The LocalCowork demo runs 67 tools across 13 MCP servers.
- It runs on one laptop — no cloud, no API keys, no data leaving the machine.
Run It
Serve in two lines, or load directly
# Serve with vLLM (OpenAI-compatible API)
pip install vllm
vllm serve “LiquidAI/LFM2.5-8B-A1B”
# Or load directly with Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = “LiquidAI/LFM2.5-8B-A1B”
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map=”auto”, dtype=”bfloat16″)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Recommended for
Agentic workflows
Tool use
Structured outputs
Multilingual assistants
On-device assistants
Less suited to
Heavy programming
Knowledge-intensive QA without retrieval
Key Takeaways
- Liquid AI’s LFM2.5-8B-A1B holds 8.3B total parameters but activates only 1.5B per token.
- It is reasoning-only, with a 128K context window and nine-language coverage.
- Non-Hallucination Rate jumped from 7.46 to 63.47 over LFM2-8B-A1B; IFEval reached 91.84.
- It decodes 253 tok/s on an M5 Max under 6 GB, and ~30 tok/s on a phone.
- Day-one support spans llama.cpp, MLX, vLLM, and SGLang, with open base and post-trained weights.
Check out the Model Weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us




